
David Schmitz
CTO
Dieser Artikel ist ursprünglich in Java Aktuell erschienen
Funktionale Programmierung hat in den letzten Jahren eine Art zweite Blüte erlebt und ist nun auch im Mainstream angekommen. In Folge hat Java 8 einige Konstrukte der funktionalen Programmierung in Java eingeführt, die im Tagesgeschäft jedoch Lücken offenbaren. Das Open Source Projekt Vavr will genau diese Lücken schließen. Sinnvolle und praktische Ideen und Konzepte aus Sprachen wie Clojure und Scala, können mit Vavr nun auch in Java auf einfache Art genutzt werden.
Warum überhaupt funktional programmieren?
Wir wollen hier keinen theoretischen Exkurs in die Vor- und Nachteile funktionaler Programmierung machen. Dennoch wollen wir den Vorteil der funktionalen Programmierung anhand eines kleinen Beispiels verdeutlichen.
Funktional geschriebene Programme vermeiden unnötige Seiteneffekte. Dazu zählen auch die im Java Umfeld standardmäßig genutzten Collections, die eine beliebte Fehlerquelle sind. Der Code konzentriert sich auf das, was man eigentlich erreichen will, statt in den Details des „Wie“ zu ertrinken. Deshalb spricht man hier von deklarativer Programmierung.
Ein einfaches Beispiel ist die Verwendung von for Schleifen im Vergleich zu Operationen wie map:
String[] names = new String[]{"Foo", "Bar", "Baz"};
// imperativ
String[] upper = new String[names.length];
for (int i = 0; i < names.length; i++) {
upper[i] = names[i].toUpperCase();
}
// funktional mit Vavr
String[] upper2 = Array.of(names)
.map(String::toUpperCase)
.toJavaArray(String.class);
Im imperativen Fall ist die eigentliche Logik “Umwandlung in Großbuchstaben” in einem Wust von Boilerplate Code verborgen. Der funktional geschriebene Code liest sich wie Prosa: Wir nehmen ein Array und wandeln jedes Element in Großbuchstaben um. Funktionale Programmierung hilft uns dabei, die Komplexität unserer Programme zu reduzieren.
Was ist das Problem mit Java 8
Java 8 hat viele Spracherweiterungen eingeführt, die aus anderen Sprachen lange bekannt waren und auf die viele Entwickler gewartet haben, wie z.B. die Erweiterung der Collections um Operationen wie filter und map, oder die Einführung von Lambdas.
Leider hat sich dabei auch schnell Ernüchterung breit gemacht. Die Verbindung von Streams und Collectors, um überhaupt filter nutzen zu können, führt bspw. oft zur „Pipeline-Hölle“:
listOfUsers
.stream()
.filter(user -> {....})
.collect(Collectors.toList());
Auch die Verwendung von Lamdbas mit Checked Exceptions ist nicht ganz so einfach, wie initial gehofft und zwingt den Programmierer zu umständlichen Konstrukten wie in diesem Beispiel:
listOfUsers
.stream()
.filter(user -> {
try {
return user.validate(); // throws Exception
} catch (Exception ex) {
return false;
}})
.collect(Collectors.toList());
Da Lamdbas in Streams keine Checked Exceptions werfen dürfen, müssen diese umständlich gefangen und gekapselt werden.
All dies hat zur Entwicklung einer Vielzahl von Bibliotheken geführt, die unter anderem diese Lücken schließen wollen. Wie auch vor knapp vier Jahren Javaslang, das nun als Vavr fortgesetzt wird.
Im Kern konzentriert sich Vavr auf:
• Funktionale Datenstrukturen: persistente, unveränderliche Datenstrukturen, z.B. List, Set, Seq,
• Abstraktionen für Werteklassen, z.B. Konstrukte wie Option und Tuple,
• funktionalen Zucker: Lift, Curry und andere Konstrukte, die aus funktionalen Sprachen bekannt sind,
• funktionale Ausnahmebehandlung,
• strukturelle Dekomposition: Pattern Matching auf Objektinstanzen.
Wir können nicht auf alle Aspekte eingehen, sondern werden nur ein paar Highlights beleuchten, die uns im Tagesgeschäft direkten Nutzen bringen.
Funktionales Java, aber bitte ohne großen Ballast
Um die grundlegenden Ideen von Vavr zu verstehen, nimmt man am besten die Tastatur in die Hand und fängt an zu programmieren.
Unter https://github.com/koenighotze/vavr-kata-demo findet sich ein Demo Projekt, das wir für unsere Diskussion nutzen. Ich lade dazu ein, das Repository zu clonen und die Anpassungen schrittweise selber auszuprobieren.
Die Demo ist eine Spring Boot Anwendung, die Sportteams verwalten soll. Wie bei Spring Boot üblich startet man die Anwendung mit gradle bootRun.
Die Anwendung exponiert die Ressource Team über einen entsprechenden Endpunkt http://localhost:8080/teams. Der Endpunkt unterstützt lesende Zugriffe über GET auf http://localhost:8080/teams für alle Teams und GET auf http://localhost:8080/teams/{id} für das Team mit der Id {id}. Über den Pfad http://localhost:8080/teams/{id}/logo kann zu dem Team mit der Id {id} das zugehörige Wappen angefragt werden.
Wir nutzen die Anwendungen um punktuell den Nutzen von Vavr zu verdeutlichen. Dabei legen wir bewusst den Blick auf einfache Vavr Funktionen, die es erlauben Schritt für Schritt Code zu verbessern und die Vorteile funktionaler Programmierung nutzen zu können. Die jeweiligen Anpassungen können auf den Branches step1-* bis step7-* nachvollzogen werden.
Optionale Ergebnisse
Als erstes Beispiel schauen wir uns die typische Nutzung von null Werten an. Null ist der größte Fehler aller Zeiten, wenn man der allgemeinen Meinung Glauben schenkt. Leider ist null häufig noch immer Teil der täglichen Arbeit.
Hier ein Beispiel aus der Demo Anwendung. Die Methode TeamInMemoryRepository#findById liefert null, wenn das Team nicht gefunden wurde. Der Controller muss entsprechend reagieren.
Team team = teamRepository.findById(id);
if (null == team) {
return notFound().build();
}
return ResponseEntity.ok(team);
Funktionale Programmiersprachen umgehen diese null-pointer Semantik, durch den Maybe bzw. Option Typ. Dieser repräsentiert entweder einen Wert falls verfügbar oder eben die Abwesenheit eines Wert.
Auch Vavr hat seine Variante. Option, die wir hier nutzen wollen. Option repräsentiert die Anwesenheit eines Wertes durch die Unterklasse Some und die Abwesenheit durch None.
Wir verbessern nun die Semantik und ändern das Repository, so dass es ein Option zurückliefert.
Option<Team> team = teamRepository.findById(id);
Um nun das Ergebnis zu nutzen, verwenden wir das Schweizer-Armeemesser der funktionalen Programmierung, map:
teamRepository
.findById(id)
.map(ResponseEntity::ok)
.getOrElse(() -> notFound().build());
Das Ergebnis liest sich wie ein einfacher Text: Suche ein Team mit der id id. Falls es gefunden wird, liefere das Team und den Status ok ansonsten liefere „not found“.
Persistente Collections
Java’s Collections sind ein häufiger Quell für Fehler.
Set<String> teams = new HashSet<>(asList("F95", "FCK"));
Set<String> moreTeams = teams;
moreTeams.add("STP");
// Ooops...Test schlägt fehlt
assertThat(teams).hasSize(2);
Die Collection mit Collections.unmodifiableList unveränderbar zu machen, ist leider nicht hilfreich. Für den Nutzer der “unveränderbaren” Liste ist das nicht sichtbar und erst zur Laufzeit offenbart sich das Problem mit einer hässlichen Ausnahme.
Set<String> teams = new HashSet<>(asList("F95", "FCK"));
Set<String> unmodTeams = unmodifiableSet(teams);
// Ooops...Exception!
unmodTeams.add("Boom");
Vavr vermeidet solche Probleme und bringt eine Vielzahl von eigenen Collections mit. Diese reichen von einer einfachen List bis hin zu eher spezialisierten Datenstrukturen wie PriorityQueue. Alle Vavr Collections sind funktionale Datenstrukturen sind, d.h. sie sind unveränderlich und persistent. Was das bedeutet wird an einem einfachen Beispiel klar.
Angenommen wir haben eine TreeSet von Teams.
TreeSet<String> teams = TreeSet.of("F95", "FCK", "FCB");
Wir fügen dieser Menge ein Element hinzu
TreeSet<String> moreteams = teams.add("STP");
assertThat(teams).hasSize(3);
assertThat(moreteams).hasSize(4);
Vavr verändert nicht die ursprüngliche TreeSet. Es wird eine neue TreeSet erzeugt und durch geschickte Zeigermanipulation ein Großteil des Ursprungsbaums wiederverwendet.
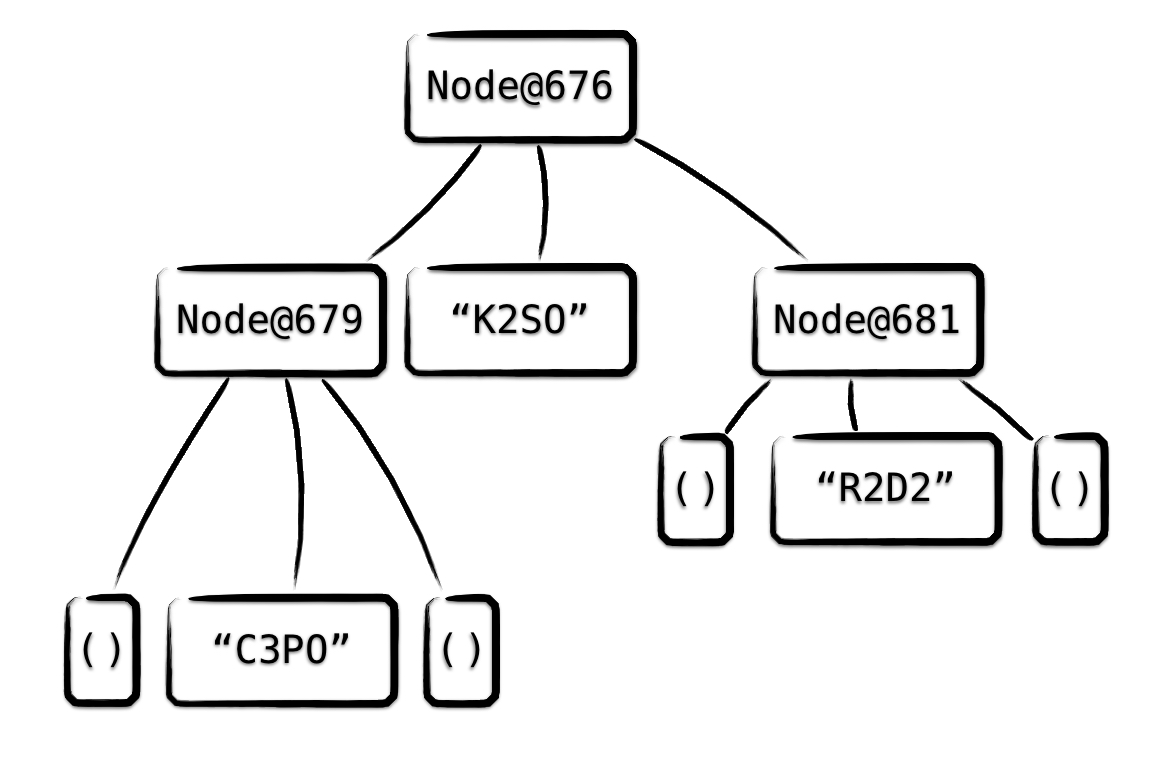
Wie das konkret funktioniert, illustriert folgende Grafik, die die TreeSet von teams illustriert. Vavrs TreeSet ist ein Baum, der aus Knoten (z.B. Node@681) und Werten (z.B. „R2D2“) besteht. Leere (End-) Knoten sind als () dargestellt.
Wird ein Element zugefügt, so kann Vavr einen Großteil der ursprünglichen Datenstruktur weiter nutzen und muss nur geschickt das neue Element einfügen. Wird im Beispiel der Wert „STP“ hinzugefügt, verwendet Vavr einen Großteil des Ur-Baums wieder – hier als gestrichelte Pfeile illustriert.
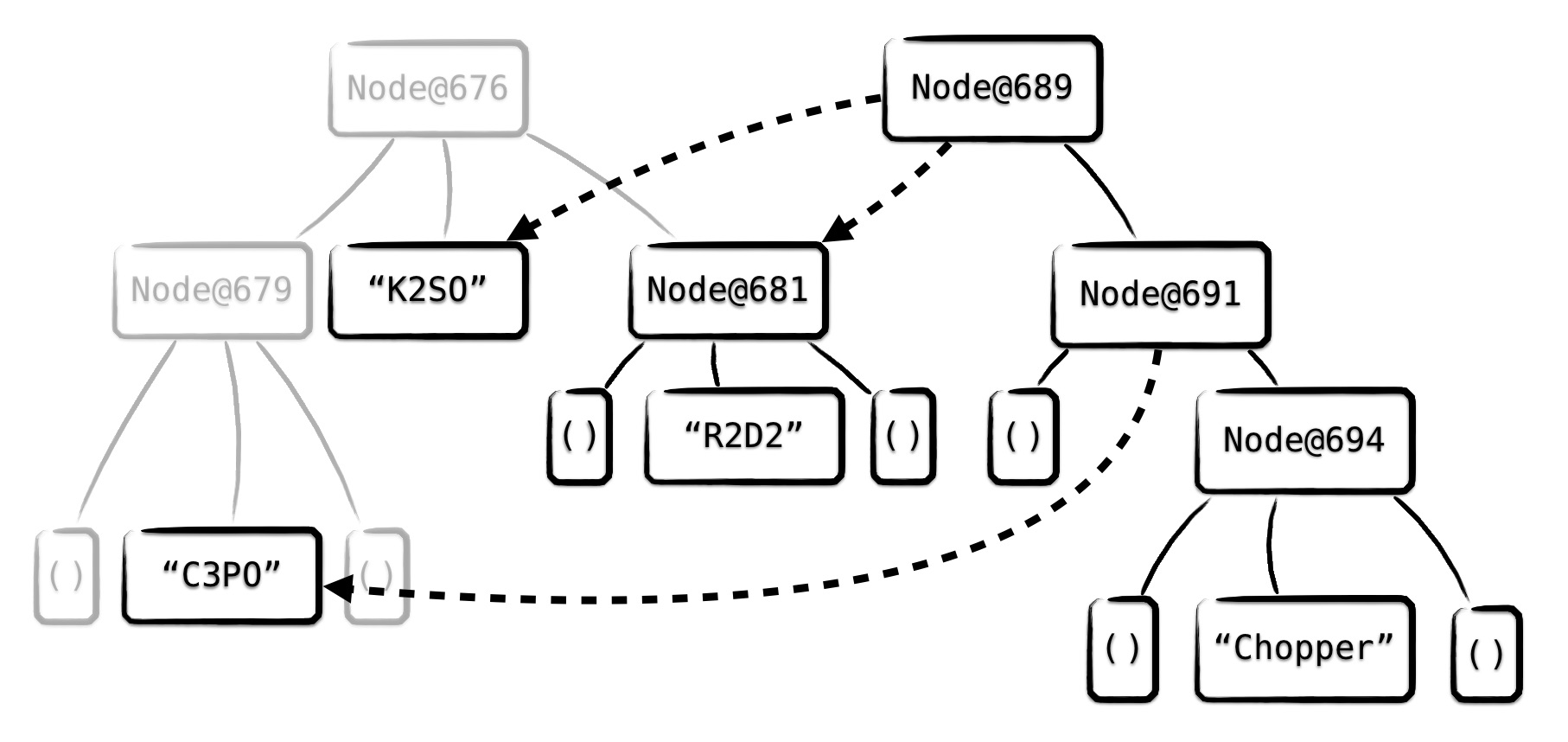
Es sollte klar sein, dass solche Operationen in der Implementierung von Vavr recht komplex sind. Für den Nutzer ist die Komplexität glücklicherweise völlig transparent.
Wer sich um die Performance sorgt, sei hier auf die Microbenchmarks von Vavr verwiesen. Wir bevorzugen immer eine seiteneffektfreie Implementierung und optimieren nur wo es Sinn macht. Im Zweifel ist der Übergang zwischen Vavr Collections und Java Collections immer nur ein toJavaSet entfernt.
Funktionale Ausnahmebehandlung
Exceptions und funktionale Programmierung sind in Java 8 ein trauriges Kapitel. Werfen wir einen Blick auf die Methode TeamsController#readTeamLogo:
String readTeamLogo (Team t) throws InterruptedException,… {
return supplyAsync(() -> {
try {
return fetchRemoteLogo(t);
} catch (IOException e) {
throw new RuntimeException(e);
}
})
.get(3000, MILLISECONDS);
}
String fetchRemoteLogo (Team t) throws IOException {
...
}
Hier wird versucht über die Methode fetchRemoteLogo das Wappen eines Teams zu laden. Dabei kann eine IOException geworfen werden. Das Ganze soll asynchron über CompletableFuture#supplyAsync mit einem Timeout von 3 Sekunden geschehen (CompletableFuture#get). Daher muss die IOException gefangen und irgendwie sinnvoll behandelt werden: Hier wird sie als RuntimeException gekapselt. Schließlich kann die Verwendung von CompletableFuture selbst noch einen ganzen Zoo an Exceptions werfen, u.a. InterrupedException. Offensichtlich ist das ganz schön viel Code für eine doch recht simple Semantik.
Mit Vavrs Try und Lift Konstrukten wird die Fehlerbehandlung funktional und übersichtlich.
Als erstes kapseln wir fetchRemoteLogo so, dass keine Exception mehr geworfen wird. fetchRemoteLogo ist eine partielle Funktion: Sie ist nur für Teams definiert, deren Logo geladen werden kann. Für alle anderen ist der Rückgabewert nicht definiert. Mit Vavrs CheckedFunction1.lift machen wir aus dieser partiellen Funktion eine totale Funktion, die obskure Syntax ist leider Java „geschuldet“:
Function1<Team, Option<String>> liftedReader = lift(this:: fetchRemoteLogo);
liftedReader liefert als Ergebnis ein Option, so dass wir einfach im Fehlerfall ein Default-Wappen nutzen können:
liftedReader.apply(team).getOrElse(default);
Lift ist ein wunderbares Mittel, um Code zu kapseln den man selber nicht mehr modifizieren kann – bspw. wenn man in einen Brownfield Projekt arbeitet und Legacy Code nutzen muss.
Wir nutzen die ge-lift-tete Variante nun in der Implementierung von readTeamLogo:
String readTeamLogo(Team t) throws InterruptedException,… {
Function1<Team, Option<String>> lifted = …;
return supplyAsync(() -> lifted.apply(t)
.getOrElse(default))
.get(3000, MILLISECONDS);
}
Besser, aber wir haben noch immer die ganzen Exceptions der CompletableFuture. Hier kommt Vavrs Try zur Hilfe.
Try kapselt einen Funktionsaufruf, der eine Exception werfen kann. Das Ergebnis ist dann entweder ein Success mit dem Ergebnis oder ein Failure mit der geworfenen Exception. Sowohl Success als auch Failure lassen sich wie Option nutzen.
Das nutzen wir nun in der Implementierung von readTeamLogo:
Try<String> readTeamLogo(Team t) {
Function1<Team, Option<String>> lifted = …;
return Try.of(
() -> supplyAsync(
() -> lifted.apply(t)
.getOrElse(default)
).get(3000, MILLISECONDS)
);
}
Diese Funktion drückt bereits durch die Signatur und den Typ der Rückgabe aus was zu erwarten ist: Try – ein Versuch einen String zu liefern, der entweder glückt, oder eben nicht.
Darüber hinaus bietet Try Operationen, die man auch von composable functions kennt. Man kann ohne weiteres mit andThen usw. mehrere Aufrufe nacheinander funktional kombinieren, ohne in einen Catch-Sumpf abzutauchen.
Try bietet aber noch viel mehr. So kann man mit Try die explizite Behandlung von Ausnahmen sauberer als mit catch-Blöcken ausdrücken:
readTeamLogo(team)
.map( /* Erfolgsfall */ )
// Behandlung der Ausnahme innerhalb der CompletableFuture
.recover(ExecutionException.class, logoFetchFailed())
// sonstige Fehlerfälle
.getOrElse(TeamsController::logoFetchTimedoutResponse);
Mit recover(Exceptiontype, recoverFunction) kann auf Ausnahmen vom Typ Exceptiontype ein Ersatzergebnis mit Hilfe der recoverFunction konstruiert werden.
Rund um Vavr
Im Vavr Ökosystem ist noch Einiges zu finden. Vavr-Jackson (https://github.com/vavr-io/vavr-jackson) ist eine Bibliothek um Vavr Datentypen in REST Schnittstellen direkt nutzen zu können. Vavr-Test ist eine Erweiterung für Property Based Testing ähnlich wie ScalaCheck. Mit Resilience4J (https://github.com/resilience4j/resilience4j) ist eine Circuit Breaker Implementierung auf Basis von Vavr. Damit kann man mit einfachen Mitteln Java Funktionen mit Circuit Breakern ausstatten, ohne auf komplexere Frameworks wie Hystrix zurückgreifen zu müssen. Mit Spring Data 2 lassen sich Vavr Datentypen sogar direkt in Repositories nutzen, hier ein Beispiel:
interface UserRepository extends MongoRepository<User, String> {
Option<User> findByPublicId(String publicId);
Seq<User> findByLastname(String lastname);
}
Spring Data generiert die notwendigen Implementierungen, die die gewünschten Vavr Strukturen liefen.
Ausblick auf 1.0
Während Javaslang bereits auf den Weg in Richtung Version 3 war, hat Vavr nun ein paar Schritte in der Versionsnummer zurückgemacht. Aktuell ist Version 0.9x verfügbar und es wird sicher durch die Refactorings noch ein paar Wochen bis zu einer 1.0 dauern. Diese Version 1.0 steht ganz im Zeichen von Aufräumarbeiten und Vorbereitungen in Hinblick auf Java 9 – insbesondere dem Modulsystem. Weiter werden einige Konzepte potentiell deprecated, z.B. das Pattern Matching auf Objektebene (http://blog.vavr.io/pattern-matching-starter/), da zukünftige Java Versionen diese Konzepte nativ unterstützen werden (http://cr.openjdk.java.net/~briangoetz/amber/pattern-match.html).
Endlich ein Allheilmittel?
Vavr ist keine Allzweckwaffe. Man wird sicher nicht die Ausdruckstärke von Scala, Haskell oder ähnlichen Sprachen in Java erwarten dürfen. Dafür ist Java auch niemals gedacht gewesen. Es ist auch klar, dass für die Nutzung mit Hibernate oder MongoDB Typkonverter geschrieben werden müssen, was man auf punktueller Ebene abwägen muss. Am Ende macht Vavr den Übergang zwischen Java und Vavr Datenstrukturen extrem einfach, so dass man immer noch ein Sicherheitsnetz hat.
Schließlich muss man in seinen Projekten entscheiden, wie viele Collection Bibliotheken parallel Sinn stiften. Vavr, Guava, Commons Collections, Eclipse Collections,… irgendwann ist es halt genug und man wählt genau eine Implementierung.
In unseren Brownfield Projekten haben sich gerade die einfachen Konzepte von Vavr, wie die hervorragend designten, funktionalen Datenstrukturen und Abstraktionen wie Option, Lazy und Try bewährt. Diese verbessern den Code und helfen insbesondere dabei die Komplexität typischer, verschachtelter Programme aufzubrechen und Legacy Code funktional zu refaktorieren. Schließlich ist an jeder Stelle erkennbar, dass Einfachheit und Fokus auf Programmierer Designziele von Vavr sind. Man kommt auch ohne einen Kurs in Monadentheorie rasch zu guten Ergebnissen.
In Summe lohnt sich der Blick auf Vavr auf jeden Fall. Wer die Vorteile der funktionalen Programmierung innerhalb von Java nutzen möchte, wird sicher viel Freude an Vavr haben.