
Christian Weyers
Architect
ETL (Extract-Transform-Load) is at the core of every data integration project. We are involved in multiple client projects ranging from the classical data warehouse to event-driven IT architectures. This range of processes forces the technologies used for data integration to broaden their functionalities quickly in order to stay up-to-date with the field’s current business needs.
What is the issue?
Modern software development relies heavily on agile working concepts which imply small incremental changes to the software. These need to be delivered quickly and in good quality. To achieve both, most projects are aiming for “continuous integration and continuous delivery” (CI/CD). The objective here is to automatically release small additions or changes to the software. Nowadays, this is often achieved via automatisation platforms such as Gitlab. These platforms allow the configuration of so-called pipelines to automate the building, testing and delivery of new code.
The key is automated testing which has already been standardised in backend and frontend development for about a decade. However, most ETL tools have been focussing on their own versioning and possess only basic built-in testing frameworks. Further, these tools often do not support the standard tool stack such as test containers, mocking tools and unit test libraries. Additionally, data integration projects are subject to complex dependencies of different data sources. Therefore, the process of mocking appropriate test data gets more complex as the underlying business model extends. In contrast to these external dependencies, internal dependencies arise from stacked integrated and highly interdependent ETL streams. This stacking of ETL streams often leads to testing scenarios which focus on highly dependent and non-exchangeable streams tailored to a specific business requirement which make isolated testing challenging.
This lack of modern testing and automatisation capabilities leads to a wide-spread focus on semi-manual developer testing, where the developer is applying exploratory testing methods – a process that is both slow and prone to errors. Moreover, developer tests are naturally similar to integration level tests, completely bypassing the level of unit testing. Consequently, from the standpoint of reliable quality assurance, ETL streams are often not systematically tested. This is, plainly spoken, inacceptable for modern software development projects. Contrastingly, the ETL part of the software needs to be treated like any other code and should be held to the same standard.
What we have done
When we started developing such a framework in late 2019, we agreed to focus on those aspects of the software that seemed to be most fragile and therefore promised the most value when tested. In ETL-development, we create generic and reusable components to manipulate data and subsequently link these to build a data integration stream. While the correctness of these reusable components is important, the reliability of the components itself is not a problem. Instead we identified the process of linking these components as the most advantageous place to start automated testing, since most bugs occur here.
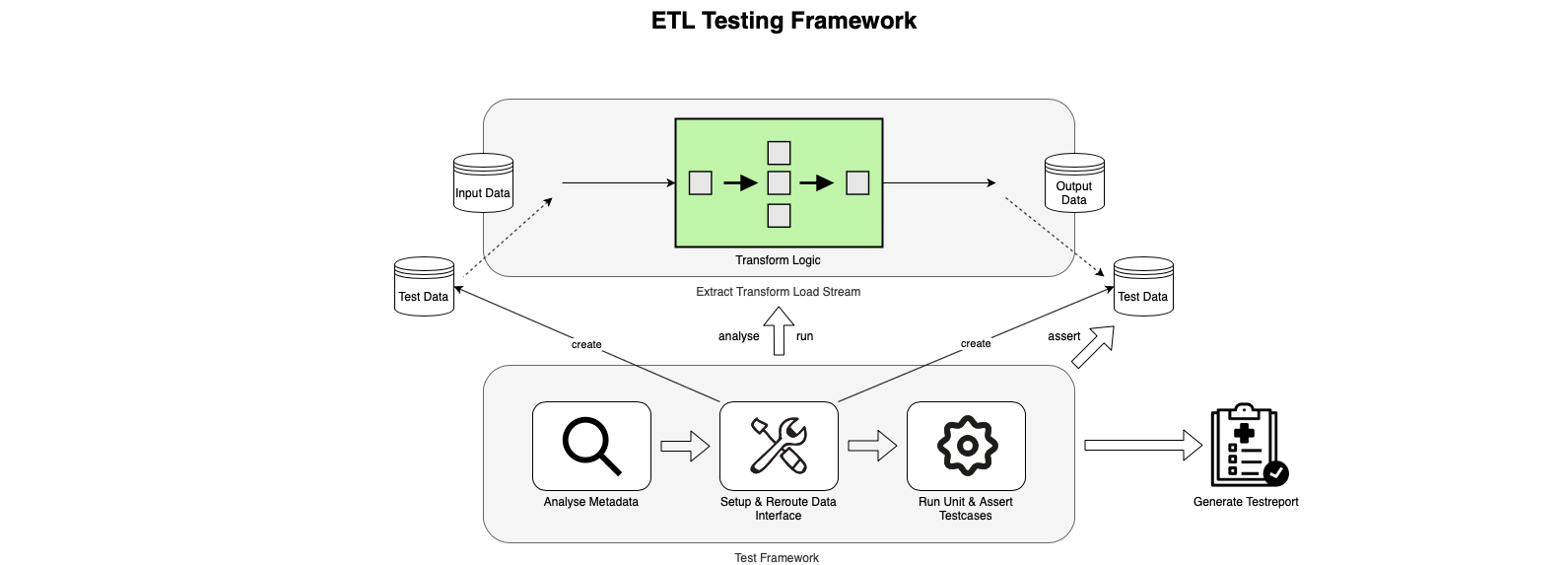
Figure 1: Schematic representation of the ETL testing framework. The framework isolates an ETL stream, analyses its required input and output database as well as file objects and creates them. Subsequently, the developer can define the input test data, which will be used for the actual test run. On completion of the test run, the output test data is re-routed and compared to the expected result. Each test run concludes with the generation of a test report.
The outcome of the development process was a framework template for automated ETL stream testing, which is schematically shown in figure 1: By interpreting an ETL stream’s metadata, the framework is able to generically mock all underlying database structures and execute ETL streams completely isolated from their successors. The same holds for other dependencies. The new framework achieves this by dynamically building the environment tailored to each ETL stream, allowing the developer to define the mock data and writing this data into the created objects. Additionally, the framework interpretes the outcome after each test and generates a test report. Also, it is easy to use, runs fast, can be installed after the development has already started as well as being integratable into CI/CD runs. With this approach, we automated a process which was, at best, done manually by developers before and often proved to be one of the most vulnerable points in a project’s testing concept.
After communicating the potential of this framework to our clients, we immediately started implementing it in some of our projects and continuously shared our experiences with colleagues to improve the framework.
Apart from having such a basic and helpful tool at hand, another benefit was that this milestone towards automated testing in ETL, inspired our colleagues to work on related subjects. One exemplary topic here is unit and component testing for which a first draft has recently been presented as part of our regular knowledge sharing events.
In addition, we work closely with our technology partners striving to enable containerization, meaning the packaging of software into virtual containers that can be tested and delivered in isolation. This can be a further milestone towards better CI/CD integration.
Other fields that are currently being worked on are improved test reporting as well as the integration of both the automated tests and the ETL technologies as a whole into the pipeline architecture of modern software development environments.
Outlook
The big lesson we learnt from working on a new testing framework, is that we should not limit ourselves by what current ETL technologies offer. By pooling resources and knowledge we can succeed in offering our clients better quality products and solutions that are tailored to their specific business needs. While it is certainly an investment to develop such a tool by our own, the potential return can be manifold. Further, as seen in this case, it can inspire a whole branch of projects and collaborations to find new solutions together and not to be satisfied by the status quo.