
Victor Warno
Senior Developer (ehem.)
In regelmäßigen Abständen bietet Senacor seinen MitarbeiterInnen die Möglichkeit, unabhängig vom Projekt tiefer in ein bestimmtes Thema oder technisches Framework einzutauchen. Dazu dient ein sogenannter 48-Stunden-Sprint, welcher sich im Mai ganz um das Thema MLOps / CD4ML drehte.
Viele Unternehmen wollen Machine Learning getriebene Business Cases etablieren, haben aber kaum Konzepte, die Modelle in Betrieb zu bringen, geschweige denn kontinuierlich zu betreiben. Dieser Problematik nimmt man sich mit MLOps / CD4ML an und möchte Möglichkeiten schaffen, den Lieferprozess von maschinell gelernten Modellen zu automatisieren und die Qualität der produktiven Modelle zu verbessern. Um MLOps hands-on an einem Machine Learning Problem zu erleben, haben sich Data Analyst Sven Upgang und Software Entwickler Victor Warno die AI Platform DataRobot für zwei Tage im Detail angesehen.
MLOps
Software Development hatte reichlich Zeit, den Deployment-Prozess von Software- Paketen zu standardisieren und entsprechende Frameworks bereitzustellen. Dies mündete schließlich in der Disziplin namens DevOps, die Prinzipien und Frameworks vereint, um Software kontinuierlich in eine produktive Umgebung zu überführen. DevOps sollte nicht nur den Verantwortlichen im Betrieb das Leben erleichtern, sondern auch Entwickler näher an den Lieferprozess und dessen Schritte heranführen. Zu diesen gehört unter anderem die Ausgestaltung der Deployment-Pipeline, das Release Management sowie das Monitoring der deployten Systeme. Doch lassen sich diese Schritte eins-zu-eins auf Machine Learning übertragen? Immerhin handelt es sich bei dem Outcome eines Model Training auch um ein Deployment-Artefakt – ein Stück Software also, das auch nach DevOps-Prinzipien geliefert werden könnte.
Was Machine Learning Modelle von traditioneller Software Entwicklung unterscheidet, ist die Vereinigung mehrerer unterschiedlicher Abteilungen unter einem Dach. Data Scientists, Data Engineers, Machine Learning Engineers, Software EntwicklerInnen, Business AnalystInnen und auch das IT Operations Team sollten für den Prozess der Lieferung in Produktion ein gemeinsames Verständnis aufbauen und den Fortschritt in einem übersichtlichen Portal verfolgen können.
Oftmals steht nach dem Training eines Modells jedoch nicht sofort fest, ob dieses letztendlich in Produktion landet. Auf ein gutes Tracking aller geführten Experimente lässt sich da nicht verzichten. Während ein Deployment eines ursprünglichen Software-Pakets durch umfangreiches Testen sichergestellt wird, sollte bei Machine Learning validiert werden, ob die Modelle auch auf Produktionsdaten gute Ergebnisse berechnen können. Auch ist mit dem Überwachen des Modells in Produktion nicht Schluss, da ein automatisierter Prozess ermitteln können sollte, wann es an der Zeit ist, ein neues Modell zu trainieren, beispielsweise sobald das bisherige nicht mehr akkurat performt.
All diese neuen Herausforderungen haben zu der Einführung des neuen Begriffs MLOps geführt, das an DevOps angelehnt ist, dessen Praktiken und Ideen sich jedoch auf das Gebiet des maschinellen Lernens spezialisieren.
DataRobot
DataRobot versucht nun mit einer Standalone Plattform eine Antwort auf diese Herausforderungen zu finden. Das 2012 gegründete Unternehmen bietet eine Low-Code-Solution für Enterprise AI, die MLOps-Prozesse automatisieren soll.
Diese werden häufig durch einen Zyklus dargestellt, der die wiederkehrenden Elemente im Betrieb eines maschinell gelernten Modells verdeutlichen soll. In diesem Artikel sollen einige Features von DataRobot entlang der wichtigsten Schritte vorgestellt werden.
Data Collection & Data Analysis
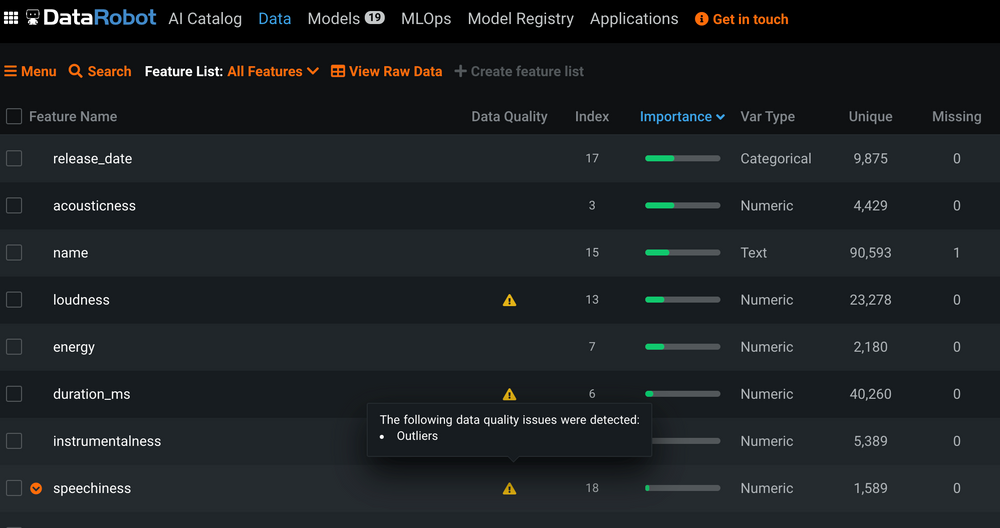
Feature Analysis
Während des Sprints haben wir ein Klassifikations- und ein Regressionsproblem näher betrachtet. Für Ersteres galt es, Brunnen in Tansania in funktional oder nicht-funktional einzuteilen. Zweiteres erforderte die Vorhersage der Popularität von Spotify-Songs auf einer Skala von 0 bis 100. Beide Arten können bei Angabe des Datensatzes und des Target Labels spezifiziert werden. Dabei kann eine CSV-Datei importiert, aber auch eine externe Datenquelle angegeben werden. Schon beim Einlesen der Daten übernimmt DataRobot eine Feature Analyse, die Datentypen und Korrelationen erkennt. Bemerkenswert ist auch die Erkennung von Outliers und Target Leakage während des Einlesens. Target Leakage ist ein Maß dafür, dass ein entsprechendes Feature bei Berechnung der Prediction in Produktion nicht zur Verfügung stehen wird.
Model Training
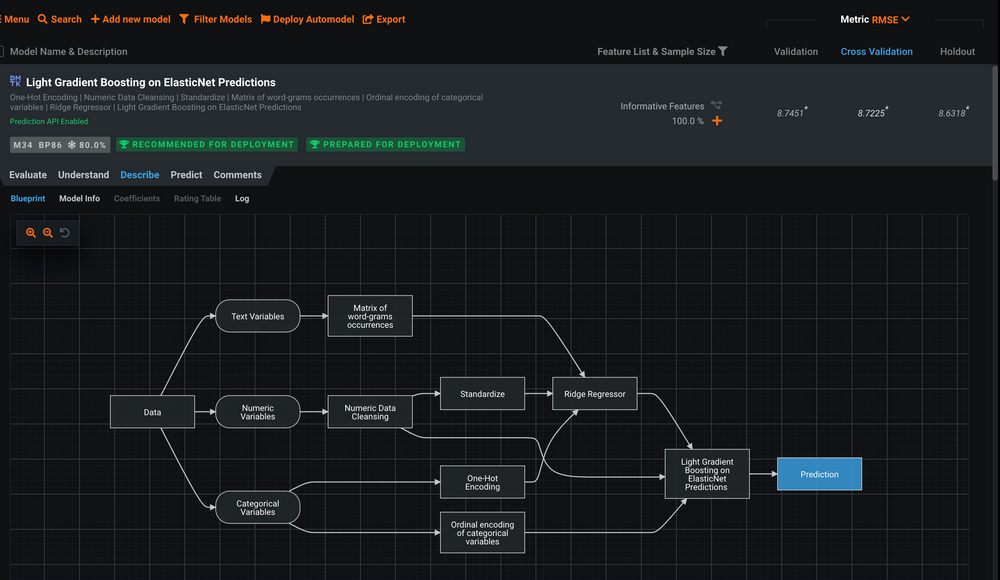
Erklärung zu einem Modell
Auch das Modelltraining kann vom AutoPilot übernommen werden. Dabei werden automatisiert verschiedene Modelle auf dem angegebenen Datensatz trainiert. Im Repertoire hat DataRobot verschiedene Modellarten, darunter Random Forest, Light, Gradient Boosting und Keras Modelle. Aber auch Model Blending und Model Stacking werden unterstützt. Nach Abschluss des Trainings werden die Modelle mit ihren Parametern in einem Leaderboard sortiert und jedes Modell kann genauer untersucht werden. Feature Importance, Learning Curves und Confusion Matrix stehen zur Analyse bereit. Schließlich wird unter der Sektion Describe noch einmal näher auf die Funktionsweise jedes einzelnen Modells eingegangen. Alle trainierten Modelle lassen sich im Bereich Model Registry einsehen, was das gewünschte Tracking aller Experimente ermöglicht.
Wer zu dem Thema “Automated Machine Learning” mehr erfahren und andere Frameworks dazu kennen lernen möchte, den könnte folgender Senacor-Blogeintrag über AutoML interessieren.
Model Deployment
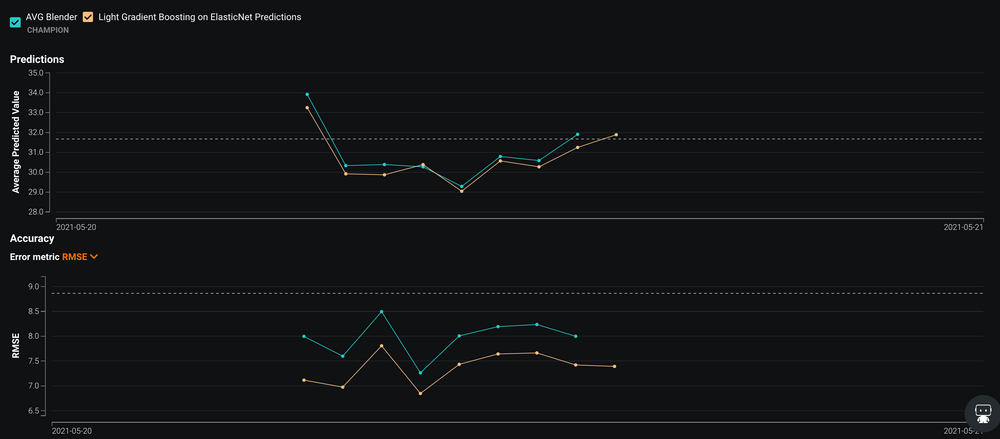
Performance zweier Modelle im Vergleich
Aus dem zuvor erwähnten Leaderboard lässt sich ein Modell per Click auf DataRobot-Ressourcen schnell und einfach deployen. Ein besonderes Feature von DataRobot ist das Champions-Challengers-Konzept: Neben dem eigentlichen Deployment kann DataRobot andere Modelle parallel laufen lassen. Dort können die Predictions für ein anderes Modell replayed werden, sodass ersichtlich wird,
wie andere Modelle im Vergleich abschneiden würden. Das beste deployte Modell wird Champion genannt, alle anderen Modelle heißen Challengers. Stellt sich heraus, dass ein Challenger besser abschneidet als der aktuelle Champion, lassen sich die beiden Modelle schnell austauschen.
Monitoring
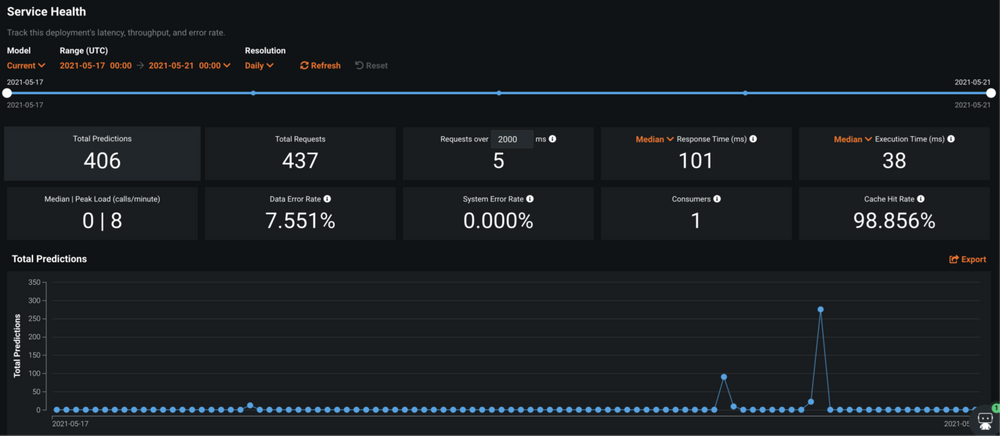
Service Health
Zur Überwachung eines laufenden Deployments bietet die DataRobot Plattform verschiedene Metriken an. Zunächst sind da fundamentale Zahlen über die Anzahl der Aufrufe und die auf eingehenden Daten berechneten Predictions. Fehlerraten sowie die Anzahl der Aufrufer (Konsumenten) des Modell-Services lassen sich bei Interesse ebenfalls einsehen.
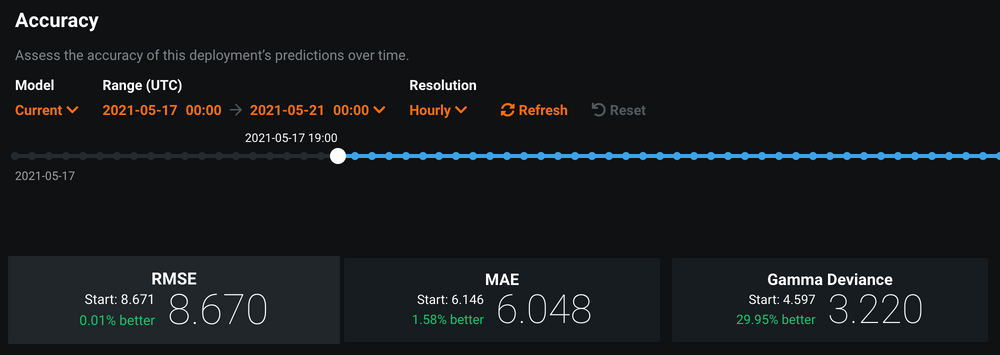
Accuracy
Von Bedeutung sind die Metriken Accuracy und Data Drift. Ist zum Zeitpunkt der Prediction die Ground Truth verfügbar (im Fall des Klassifikationsproblem also die korrekte Klasse für den gegebenen Brunnen), lässt sich messen, wie sehr sich die vom Modell produzierten Predictions von den korrekten Werten unterscheiden. Diese sogenannte Accuracy lässt sich auf verschiedene Arten berechnen und DataRobot bietet dafür auch mehrere Metriken an. Die Ground Truth kann als CSV File hochgeladen werden. Mithilfe einer Association ID kann diese dann zum ursprünglichen Modell-Input und zur Prediction gematched werden.
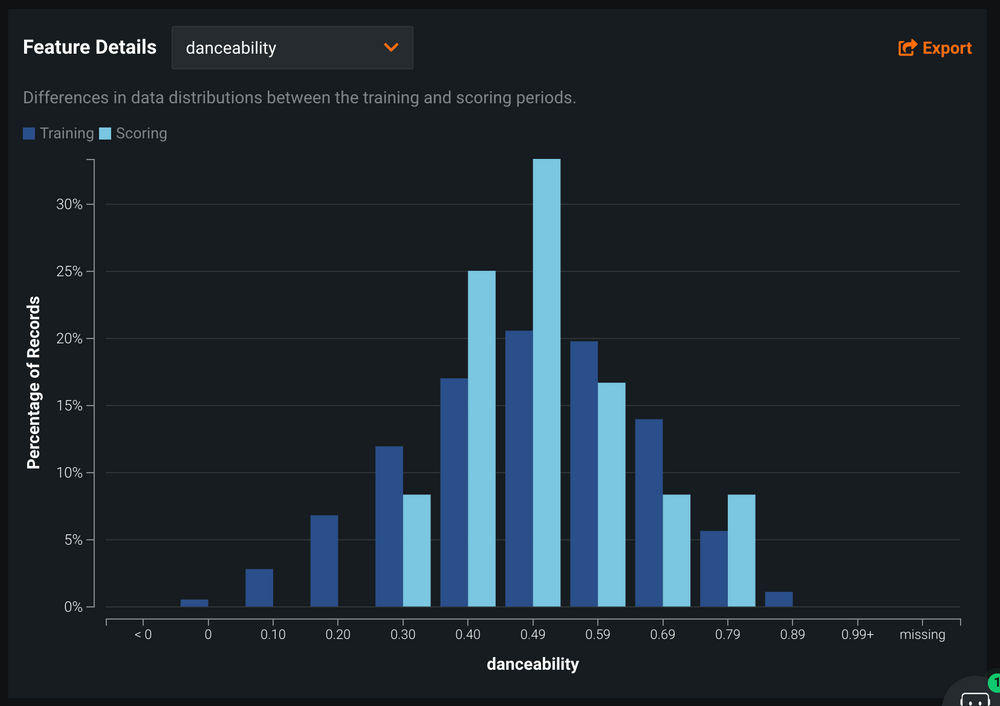
Data Drift
Data Drift lässt sich aus den bestehenden und beobachteten Daten berechnen – es bedarf keines weiteren Inputs. Dieses Konzept verdeutlicht, wie sehr sich die Verteilung eines oder mehrerer Features im Trainingsdatenset von der Verteilung in den Daten unterscheidet, die in Produktion ins Modell geflossen sind. An einem Beispiel veranschaulicht bedeutet das: Wenn das Modell lediglich auf Songs vor 2000 trainiert wurde, in Produktion jedoch nur Songs der letzten 20 Jahre verarbeitet werden, könnte das Modell signifikant schlechtere Leistung liefern.
Retraining
Sollte einer der genannten Metriken einen Schwellenwert erreichen, der das Degradieren des Modells impliziert, kann man sich eine Notification zusenden lassen. Daraufhin sollte ein Retraining angestoßen werden, wobei das Trainingsset durch die Daten erweitert werden sollte, die das Modell in Produktion entgegengenommen hat. Leider haben wir während unseren Arbeiten keine Möglichkeit gefunden, auf die Predictions zuzugreifen. Als Workaround haben wir die einkommenden Daten selbst in einer Datenbank gespeichert und in DataRobot eingebunden. Dadurch können wir in DataRobot eine regelmäßige Synchronisierung einstellen, sodass beim nächsten Training auch diese Daten genutzt werden können.
Fazit
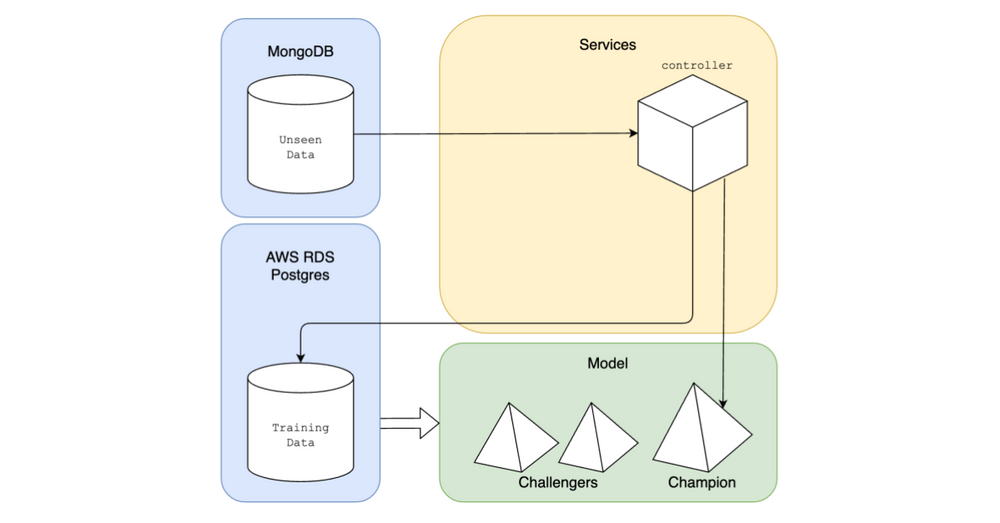
Architektur. Modelle von DataRobot trainiert und restliche Komponenten innerhalb des Sprints aufgesetzt
In unseren Use Cases ließ sich die DataRobot Plattform durch die intuitive UI schnell und problemlos einrichten. Die meisten MLOps-Prozesse lassen sich durch DataRobot implementieren; auf menschlichen Input kann man jedoch nicht ganz verzichten, wie das Retraining zeigt. Möchte man ein deploytes Modell mit Daten versorgen, bietet DataRobot eine gut dokumentierte API an. So stellt DataRobot beispielsweise Python Code Schnipsel zum schnellen Einbinden in andere Services
bereit. Das Monitoring ist ausgereift, hier jedoch nur für Regressionsprobleme. Ein entsprechendes Monitoring für Klassifikationen ist noch in der Beta-Phase. Nichtsdestotrotz überzeugt DataRobot auch durch eigens entwickelte Ideen wie die für Business AnalystInnen wichtige Einbindung von Governance als auch manuelle Steuerung von Inputwerten namens Humility. Für eine übersichtliche, weitgreifende Einführung in die Welt von MLOps reicht die Platform von DataRobot allemal.