
Marlon Alagoda
Senior Developer (ehem.)
The last couple of weeks two colleagues of mine and myself got the opportunity to build a Facebook Chatbot. Chatbots are the perfect fit for serverless architectures. As soon as a user starts writing to your bot, a webhook gets called, handles the request and replies to the user. We decided to use AWS lambdas for our webhooks, because … because they are awesome! There are many other blog posts which elaborate this statement in great detail. We did not spend a single second thinking about server infrastructure, operations, scaling or costs. The first million of lambda requests per month are free. AWS spins up your lambda, containing you logic which is handling the bot requests and puts them to sleep if not needed anymore. Wait, what? The first million requests are free? Yes, you most probably start paying only if you get so many requests you already earn money, there are no hardware or infrastructure costs at all before you’ve used your free tier limits. However, there is a small catch. The AWS toolbox is so great, easy and cheap, once you start using their ecosystem you cannot escape. Full vendor-lock! Although it was tried several times, there is no sense in using AWS but trying to abstract it. Enforce it! Use everything you can get. So we did and used DynamoDB to store our Chatbot users and application data.
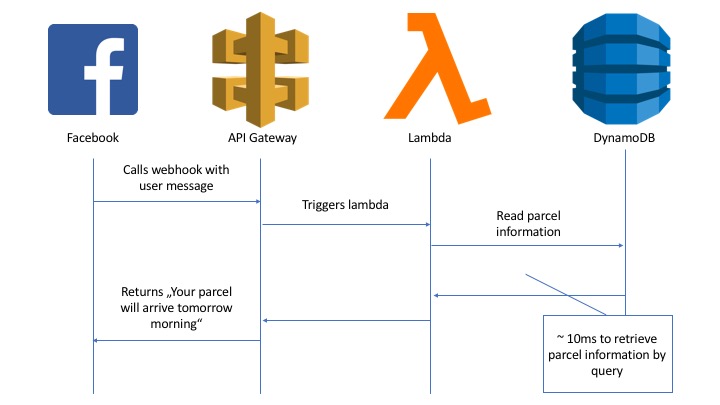
When we started to use DynamoDB I found it quite confusing, so I would like to share some key-findings after using it for some days. This article aims for readers, who hardly know anything about this database and are keen to learn something new.
Let’s go
I’m used to work with relational databases, as well as NoSQL document-stores like MongoDB. Using DynamoDB which is, according to their documentation, a mixture of a document and a key-value store, should be straight forward, I thought. Creating a connection to DynamoDB was super easy. We used the official AWS Javascript SDK and a lib from AWS labs to abstract low-level operations.
const aws = require('aws-sdk')
const DOC = require('dynamodb-doc')
aws.config.update({region: 'eu-central-1'})
const docClient = new DOC.DynamoDB()
As always at AWS, IAM takes care of the authorization from outside your code, which is admittedly a concept that can take a (short) time to understand, but once understood, it’s much easier than your normal day to day secret and permission management.
Next, similar as within the MongoDB environments I’m used to, I tried to retrieve a customer by a given field …
const params = {
TableName: 'digital_logistics_customer',
KeyConditionExpression: 'fb_psid = :key',
ExpressionAttributeValues: {
':key': psid
}
}
docClient.query(params, (err, res) => {
// Failes with "Query condition missed key schema element: customer_id"
})
… which did not work out. Of course I’m familiar with the concept of indexing fields to increase operation speed, but it has always been optional. With DynamoDB, being a key-value store as well, you can only perform operations on indexed fields. After I’ve realised that I went back to the AWS web console, I set up a new index called “fb_psid-index” and added IndexName: 'fb_psid-index' to the param object.
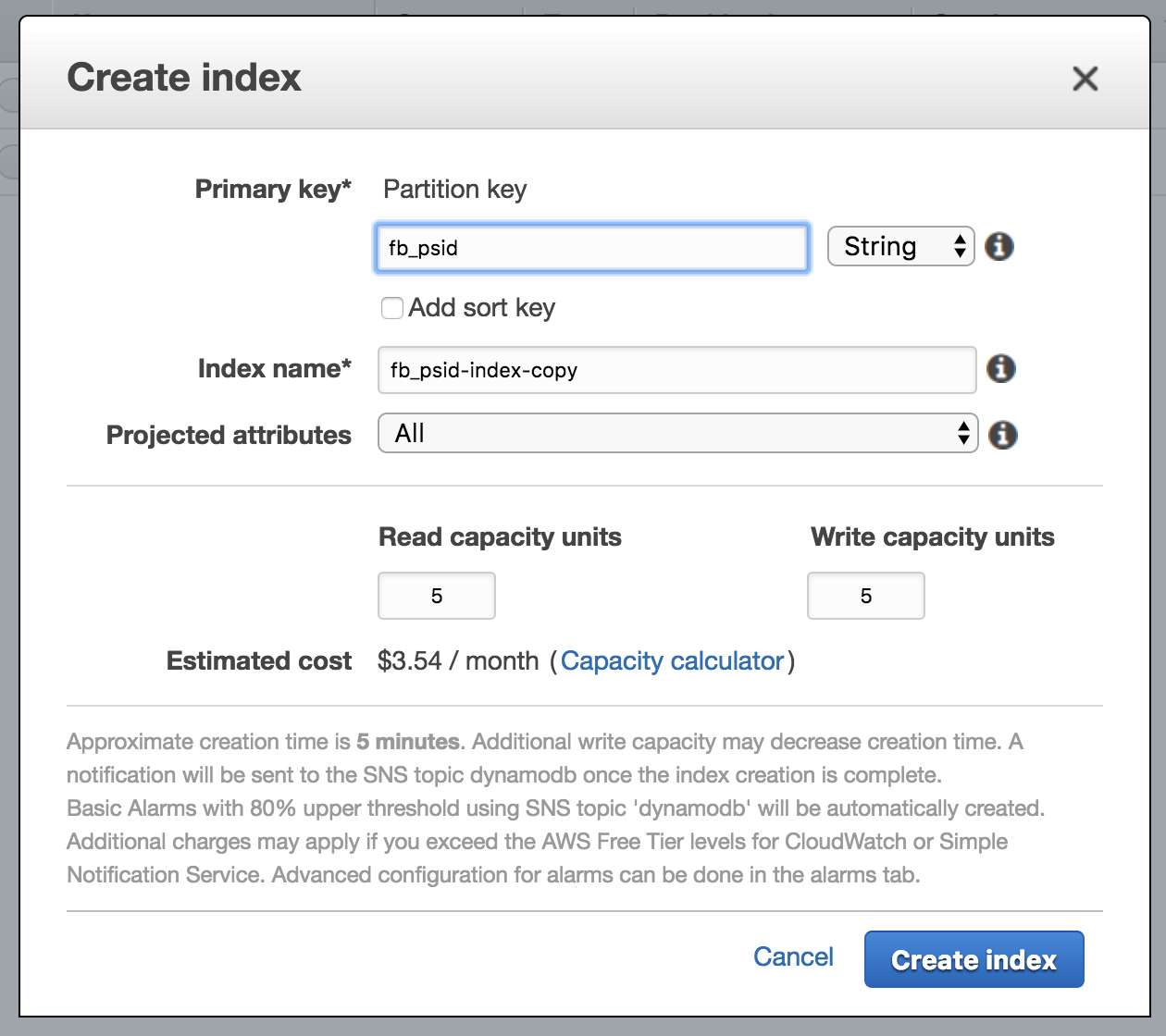
Suddenly the code above worked! But what if I want to query other fields? Since Amazon has to replicate your whole database for every new index, they will also bill you for every new index, which is the reason you cannot simply create a key out of every field. There are four operations to read and four operations to write or update data to and from DynamoDB. Which operation you should use is a matter of trade-offs, as it always is at software development (and life?). Let me help you making this decision!
Keys
There are two types of Primary Keys:
- Partition Key
- Partition and Sort Key (Aka Composite Primary Key)
When creating your DynamoDB you have to decide which type you want to use for your table. Either you create only a partition key or a partition and a sort key. The second option is called Composite Primary Key. Depending on the type of your Primary Key (composite or not?) you are more flexible or restricted when running read and write operations, which I will explain later. You should choose your Primary Key in a way that they have very distinct values from each other, in order to ensure an even distribution of your data over different partitions. There are request limits per partition, if your data distribution is higher it’s less likely you hit these limits.
In addition to a higher distribution “Sort Keys” (also called “Range Keys”) can be used to make queries and they keep your data in order. Results by default will always be ordered by your Sort Key.
Beside Primary Keys there are Secondary Indexes. You can use Secondary Indexes to query your database, but as I said, Amazon will bill you for having them. Once more you have to choose between two types. There are Global Secondary Indexes, which contain a Partition and a Sort Key and Local Secondary Indexes which have the same partition the Primary Key has, but a different Sort Key. When using a Partition and Sort Key it’s more likely you get a higher throughput due to higher distribution of your data over the partitions.
Operations
Why the hassle? Depending on your choices when creating keys you can interact with your database differently.
Put- and GetItem operations need the full Table Primary Key, which can consist of two fields, if it is a Composite Key. You cannot use Index Primary Keys (aka Secondary Indexes) for those operations.
const params = {
Item: {
fb_psid: 123, // <- partition key
customer_id: 734 // <- sort key
name: "Peter"
},
TableName: 'digital_logistics_customer'
}
docClient.putItem(params ...)
const params = {
Key: {
fb_psid: 123, // <- partition key
customer_id: 734 // <- sort key
},
TableName: 'digital_logistics_customer'
}
docClient.getItem(params ...)
Query is more flexible then GetItem. You can query your database by the Table or Index Partition Key. You can set KeyConditionExpression to define a subset of all data you want to receive.
const params = {
ExpressionAttributeValues: {
":v1": 84923
},
KeyConditionExpression: "parcel_id = :v1",
TableName: "digital_logistics_parcel"
}
Scan is the most flexible read operation. Your database does not use the advantages of hashing and indexing, but filters your data during an expensive full table scan based on a FilterExpression.
To use Update- and DeleteItem you need a Table Primary Key as well. There are more operations for doing batch operations which I will not cover in this article.
Data types
“DynamoDB is a NoSQL database and is schemaless“. With the Primary Key being an exception, you have to specify data types. However, you can! Javascript, as well as Java clients can use data type definitions for mapping database values to variables in the programming language you favor.
DynamoDB supports scalar types, document types and set types. If you want to save a single value, which is scalar typed, you can choose between saving a number, string, binary, boolean and null. Document types have the same structure you would expect a JSON to have. DynamoDB supports up to 32 level deep nested lists and maps. If you want to save a list of scalar types you can use sets.
If your client is smart, it will convert a JSON containing different data types to a corresponding DynamoDB JSON.
const params = {
TableName: 'test-partition-key-only',
Item: {
'partition-key': '123',
'nested-map': {
'a-string': 'I am a string',
'a-boolean': true,
'nested': {
'a-number-list': [1, 2, 3]
}
}
}
}
docClient.putItem(params, ...)
The Javascript Client we use, maps the programming data type to DynamoDB data types.
{
"nested-map": {
"M": {
"a-boolean": { "BOOL": true },
"a-string": { "S": "I am a string" },
"nested": {
"M": {
"a-number-list": {
"L": [
{ "N": "1" },
{ "N": "2" },
{ "N": "3" }
...
}
When reading from DynamoDB the client uses the data type information to initialize the variables in the programming language’s equivalent data type.
Wanna know more?
I hope you found my introduction to DynamoDB useful. Of course there is much, much, much more to know. I will deep dive into this database technology by further reading the following links, so could you:
- Official DynamoDB developer documenation for more information about data types, naming conventions and read and write operations.
- Choosing the Right DynamoDb Partition Key
- JS AWS DynamoDB SDK is a very well documented JS API.
- Hava a look at our chatbot and our db.js files for implementation details.